
 Integrated application systems are infrastructure systems pre-integrated with databases, applications software or both, providing appliance-like functionality for Big Data solutions, analytic platforms or similar demands. For ISVs, there are five key reasons to consider delivering your Big Data/analytics solutions in the form of integrated applications systems benefits that can make the difference between market-moving success and tepid sales and profits.
Integrated application systems are infrastructure systems pre-integrated with databases, applications software or both, providing appliance-like functionality for Big Data solutions, analytic platforms or similar demands. For ISVs, there are five key reasons to consider delivering your Big Data/analytics solutions in the form of integrated applications systems benefits that can make the difference between market-moving success and tepid sales and profits.
Operational Environment:
The typical IT enterprise evolved to its current state by utilizing standards and best practices. These include simple things like data naming conventions to more complex ones such as a well-maintained enterprise data model. New data-based implementations require best practices in organization, documentation and governance. With new data and processes in the works you must update documentation, standards and best practices and continue to improve quality.
Costs and benefits of new mainframe components typically involve software license charges. The IT organization will need to re-budget and perhaps even re-negotiate current licenses and lease agreements. As always, new hardware comes with its own requirements of power, footprint, and maintenance needs.
A Big Data implementation brings additional staff into the mix: experts on new analytics software, experts on special-purpose hardware, and others. Such experts are rare, so your organization must hire, rent, or outsource this work. How will they fit into your current organization? How will you train current staff to grow into these positions?
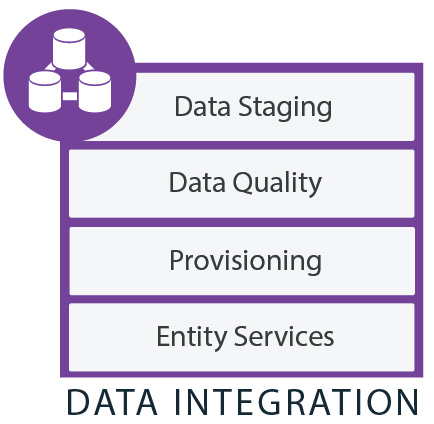
Start with the Source System:
This is your core data from operational systems. Interestingly, many beginning Big Data implementations will attempt to access this data directly (or at least to store it for analysis), thereby bypassing succeeding steps. This happens because Big Data sources have not yet been integrated into your IT architecture. Indeed, these data sources may be brand new or never accessed.
Those who support the source data systems may not have the expertise to assist in analytics, while analytics experts may not understand the source data. Analytics accesses production data directly, so any testing or experimenting is done in a production environment.
Analyze Data Movement:
These data warehouse subsystems and processes first access data from the source systems. Some data may require transformations or ‘cleaning’. Examples include missing data or invalid data such as all zeroes for a field defined as a date. Some data must be gathered from multiple systems and merged, such as accounting data. Other data requires validation against other systems.
Data from external sources can be extremely problematic. Consider data from an external vendor that was gathered using web pages where numbers and dates were entered in free-form text fields. This opens the possibility of non-numeric characters in numeric data fields. How can you maximize the amount of data you process, while minimizing the issues with invalid fields? The usual answer is ‘cleansing’ logic that handles the majority of invalid fields using either calculation logic or assignment of default values.

Review Data Storage for Analytics:
This is the final point, the destination where all data is delivered. From here, we get direct access to data for analysis, perhaps by approved query tools. Some subsets of data may be loaded into data marts, while others may be extracted and sent to internal users for local analysis. Some implementations include publish-and-subscribe features or even replication of data to external sources.
Coordination between current processes and the big data process is required. IT support staff will have to investigate whether options to get early use of the data are available. It may also be possible to load current data and the corresponding big data tables in parallel. Delays in loading data will impact the accuracy and availability of analytics; this is a business decision that must be made, and will differ from implementation to implementation.
Greater solution consistency:
In an integrated application system, you integrate the hardware and software for your product, so you control the environment that supports your product. That ensures your Big Data and analytics applications have all the processing, storage, and memory resources they need to deliver optimal performance on compute-intensive jobs. In short, your application runs the way it was designed, so customer satisfaction is optimized.
Better system security:
Analytics and other Big Data systems frequently deal with financial, medical or other proprietary information. By delivering your product as an integrated application system, you can build in the security tools necessary to prevent access by unauthorized users, hackers or other intruders. Your application is safer, so your customers gain confidence in your products.
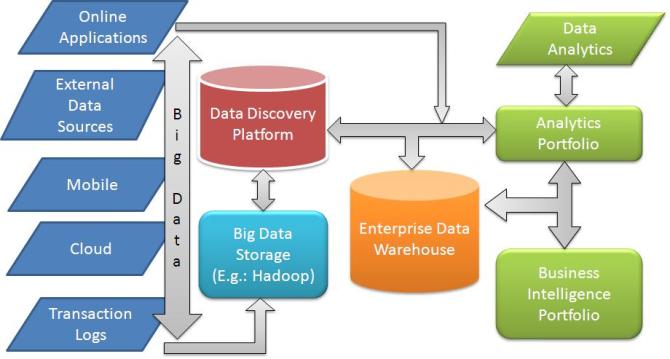
The conclusion:
Big data today has scale-up and scale-out issues. Further, it often involves integration of dissimilar architectures. When we insist that we can deal with big data by simply scaling up to faster, special-purpose hardware, we are neglecting more fundamental issues.
